Lab 10: Neural Networks
Due Date and Links
-
Lab due on your scheduled lab day
-
Lab accepted for full credit until Monday, April 13, 11:59 pm Eastern
-
Direct autograder link https://autograder.io/web/project/3834
In Lab 9, you built a linear regressor to predict song release years for a subset of the Million Song Dataset. Linear Regression is a great way to get predictions from data. However, one shortcoming of this technique is that it is “linear”: linear regressors cannot learn non-linear patterns in data. Neural networks add non-linearity, which makes them more complex but also more adept at learning patterns in data that linear regression might miss.
In today’s lab, we will extend on Lab 9 to build a small neural network from scratch using numpy with the same goal as Lab 9: to predict song release years from the Million Song Dataset based on information about the song’s audio features. You will implement the core pieces of a neural network: activation functions, a fully connected layer, and the logic for making predictions and training. We’ll then compare the results of your neural network with the results of your linear regressor to see which one performs better on our data.
This lab has one code file:
neural_net.py: You will implement parts of aNeuralNetclass that trains a 3-layer neural network to predict song release years.
NOTE: This lab builds on Lab 9. You will use the same YearPredictionMSD dataset. Refer to the lab 9 spec for a reminder on how that dataset is structured, but like last time, the details of the dataset are not important for our work here.
Starter Files
You can download the starter files using this link. The starter files include:
neural_net.pydata/YearPredictionMSD_train.txtdata/YearPredictionMSD_test.txt
You will submit only your neural_net.py file to the autograder.
Tasks to Complete
To complete this lab, you need to implement the following NeuralNet methods:
- Activation functions (used inside the network to add predictive power):
relu()relu_derivative()sigmoid()sigmoid_derivative()
- Core operations:
fc()— fully connected layerforward()— runs data through the network to get layer outputs and predictions (used by bothtrain()andpredict())predict()— returns predictions for test data
- Training (inside
train()):- Forward pass
- Error computation
- Backward pass
- SGD update
Some of the code has already been provided. You need not and should not change any of the given starter code except where you see TODO comments or placeholder return values.
Introduction
Parameter Names
In our linear regression work, the parameters of the model to be learned from the training set were stored in the vector \(w\). For a linear regression model with just one input, the prediction \(\hat{y}\) is computed as \(\hat{y} = w_0 + w_1 x\). For two inputs (\(x_1\) and \(x_2\)), the prediction is \(\hat{y} = w_0 + w_1 x_1 + w_2 x_2\), and so on for more inputs. Sometimes, instead of calling the entire \(w\) vector the weights, we call $w_0$ the bias (often renaming it to \(b\)) and the other \(w\)’s the weights. This practice is more commonly followed for neural networks, and so we will follow it here as well.
What is a Neural Network?
A neural network consists of multiple connected layers. Each layer does some computation as part of the process of making a prediction. The first layer takes its inputs directly from the dataset, and passes its computed outputs on to serve as the inputs to the second layer. The second layer then does a different calculation and passes its outputs on to the third layer, and so on, until the last layer finally outputs a prediction.
Types of Layers
We will consider two main categories of layers: Fully Connected (FC) layers and Activation layers:
- Fully Connected (FC) Layers
- What is a unit?:
- To understand a fully connected layer, we must first consider a unit. A unit is a linear regression model, except that its output is usually not the final prediction, but rather just an intermediate calculation.
- A unit computes \(b + \sum_{i} w_i x_i\), or, written with a dot product, \(b + w \cdot x\). That is, it takes in some inputs (vector \(x\)), multiplies them by weights (vector \(w\)), adds a bias (a number \(b\)), and outputs a single number. Thus, a unit performs a linear transformation on its input.
- The \(w\) vector and the \(b\) values are the parameters of the unit to be learned from the training data.
- An FC layer is a collection of units.
- A fully connected layer consists of several units. That is, a fully connected layer is like having several linear regression models stacked on top of each other.
- All inputs into a fully connected layer are sent to all units, hence “fully connected”. Visually, this makes a “web” pattern as you can see in the diagram further below.
- Each unit performs its own linear transformation \(b + w \cdot x\), and thus produces its own output.
- The output of the fully connected layer is a vector where each element is the output of one unit.
- Since each unit has its own weight vector and bias, the parameters of a fully connected layer are a matrix of weights \(W\) (where each row is the weight vector for one unit) and a vector of biases $b$ (where each element is the bias for one unit). These are the parameters of the fully connected layer to be learned from the training data.
- What is a unit?:
- Activation Layers
- An activation layer applies a non-linear function to its input. This non-linear function is sometimes called an activation function. It controls to what extent values are transformed or filtered as they pass through the network.
- One common activation function is sigmoid (\(\text{sigmoid}(z) = 1 / (1 + e^{-z})\)) that we’ve seen a few times this semester. An activation layer using sigmoid is often called a sigmoid layer.
- Another common option is ReLU (\(\text{ReLU}(z) = \max(0, z)\)), making a ReLU layer.
Training a Neural Network
You may recall for linear regression that we can use the formula \(w = (X^T X)^{-1} X^T y\) to compute the weights that minimize the mean squared error. This formula is not applicable for neural networks because of the non-linear activation layers. Instead, we use a technique called Stochastic Gradient Descent (SGD) to learn the parameters of the network. SGD is an algorithm that iteratively updates the parameters of the model in the direction that reduces the error of the model’s predictions.
Network Architecture for this Lab
For this lab, we’ll use a network of the following structure:
Input → FC → ReLU → FC → Sigmoid → FC → Output
The diagram below illustrates the neural network. Notice that all inputs are fed into each unit in FC 1. The outputs of FC1 are fed into the ReLU layer that simply computes ReLU on each output separately. These ReLU outputs are then fully connected into FC 2, with each output going to sigmoid, then fully connected into FC 3, which produces a single value as a final prediction. The flow of data from the inputs to the output is called the forward pass. In this lab, a forward pass through the model will produce a prediction \(\hat{y}\) for the release year of a song.
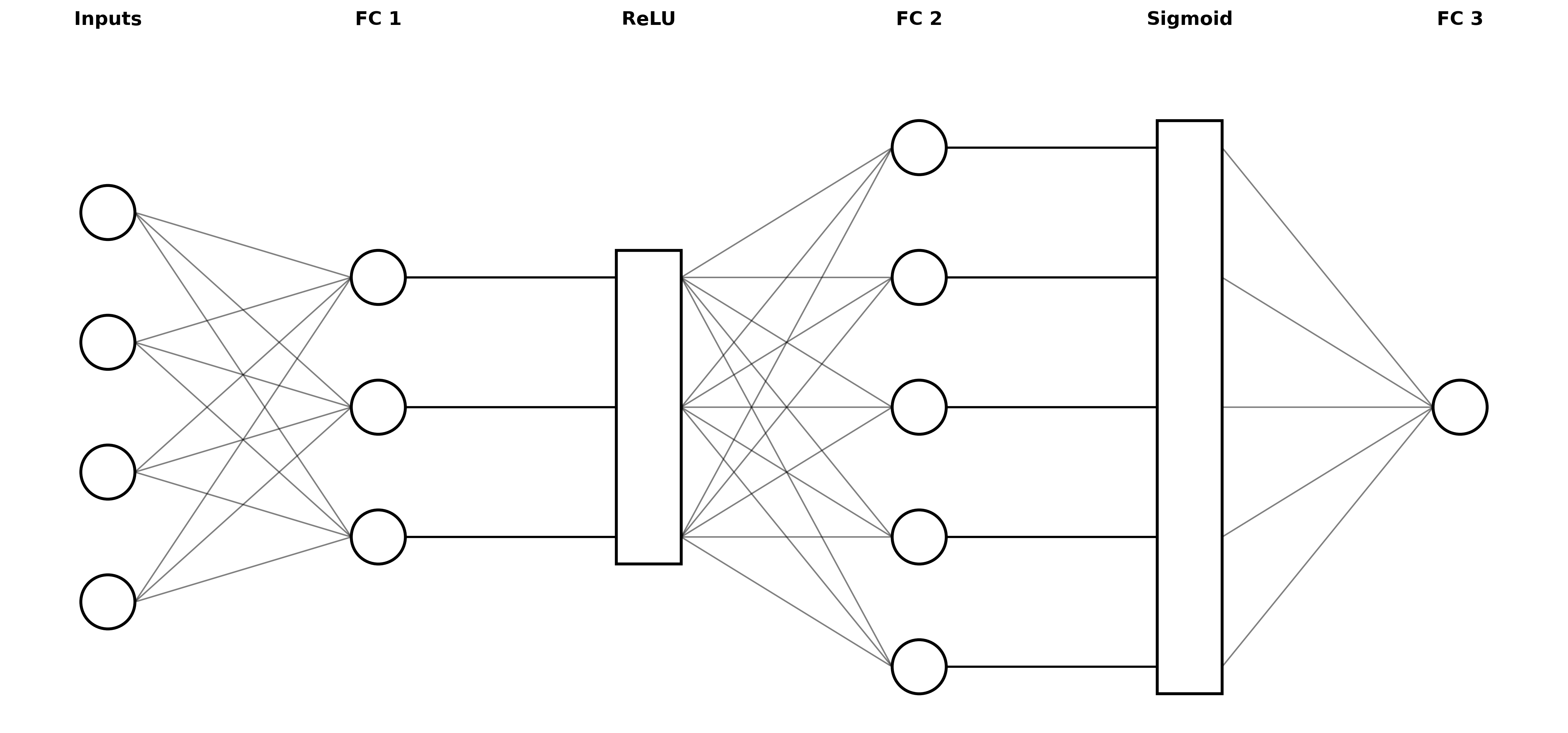
We will also compute errors in predictions and update the parameters of the model to reduce that error, in what is called the backward pass. The formulas for the backward pass are derived from calculus, including a concept called the derivative. If you are not familiar with these concepts, that’s no problem at all for this course. We’ll give you the formulas you need, and in class we’ll briefly discuss the intuition behind them.
Part 1: Activation Functions
Activation functions (in activation layers) change the values that pass through the network. They distinguish neural networks from linear regression by adding non-linearity. Without them, stacking multiple FC layers would be equivalent to a single linear model. ReLU and Sigmoid are two types of activation functions. In this part, we’ll write the implementations we need for both sigmoid and ReLU, for both the forward and backward passes.
ReLU
ReLU (Rectified Linear Unit) applies the following calculation to every element in the input: if the element is positive, leave it the same. Otherwise, set it to 0.
- If
x > 0, outputx - If
x <= 0, output0
Implement ReLU in NeuralNet.relu().
Hint: Look up and use the np.maximum function for a vectorized implementation of ReLU. Do not use a loop.
ReLU Derivative
The derivative of ReLU is used during the backward pass. Don’t worry if you are not comfortable with the math - we don’t need it here. It can be represented by the following algorithm for every element of the input:
- If
z > 0, output1 - If
z <= 0, output0
Implement the derivative of ReLU in NeuralNet.relu_derivative().
Ensure you convert the resulting array to an array of floats before returning. You should vectorize this function - do not use a loop.
Sigmoid
Sigmoid squashes values into the range (0, 1). The formula is:
\[\text{sigmoid}(z) = \frac{1}{1 + e^{-z}}\]However, when \(z\) is very large or very small, the sigmoid can become extremely small or large as well, which can lead to issues with our neural network (if you’re interested, look up exploding and vanishing gradients!). So, before computing the exponent, clip x to the range [-500, 500] using np.clip(x, -500, 500). This prevents overflow.
Implement the Sigmoid in NeuralNet.sigmoid(). Ensure you vectorize this, and do not use a loop.
Sigmoid Derivative
Just like NeuralNet.relu_derivative(), we will use the sigmoid derivative in our backward pass. The formula for the sigmoid derivative (where we refer to the input as z) is:
Implement the Sigmoid derivative in NeuralNet.sigmoid_derivative(). Ensure you vectorize this, and do not use a loop. Call NeuralNet.sigmoid() in this function.
Part 2: Fully Connected Layer
A fully connected (FC) layer computes:
\[\text{FC}(X, W, b) = X \cdot W + b\]Xis the input (a matrix where each row is one data point)Wis the weight matrixbis the bias vector
This should look familiar - it is the exact same formula as we used in Lab 9. Here, X · W means matrix multiplication. This can be done in numpy with the function np.dot().
Implement the FC layer in NeuralNet.fc(). Ensure you vectorize this. Do not use a loop.
Part 3: Forward Pass
You will now implement NeuralNet.forward(). This function runs the actual layer pipeline and is called by both train() and predict(). forward() will compose your fc(), relu(), and sigmoid() implementations as follows:
- Call
NeuralNet.fc()withX,self.W1, andself.b1as arguments. Store the output asfc1_output(first FC layer). - Call
NeuralNet.relu()withfc1_outputas its argument. Remember, ReLU does not use weights or biases. Store the output asrelu_output. - Call
NeuralNet.fc()withrelu_output,self.W2, andself.b2as arguments. Store the output asfc2_output(second FC layer). - Call
NeuralNet.sigmoid()withfc2_outputas its argument. Remember, sigmoid does not use weights or biases. Store the output assigmoid_output. - Call
NeuralNet.fc()withsigmoid_output,self.W3, andself.b3as arguments. Store the output aspred. This represents our neural net’s predictions forX(each row ofpredis the prediction \(\hat{y}\) for the corresponding data point inX).
Refer to this diagram:
 .
.
Return these five values as a tuple, in that order:
(fc1_output, relu_output, fc2_output, sigmoid_output, pred)
Part 4: Train
The train() method teaches the network by:
- Performing the forward pass for one data point at a time
- Computing how wrong the prediction was using mean squared error (the loss)
- Updating the \(W\)’s and \(b\)’s to reduce that error.
Put together, those three steps make up an “epoch”. We perform 50 epochs, and the \(W\)’s and \(b\)’s improve a little bit each time.
The starter code already provides:
- Shuffling the data each epoch: this is an ML convention to ensure that the neural network isn’t just learning something from the order of the data
- The backward pass and SGD to recompute and update the \(W\)’s and the \(b\)’s
- Printing the RMSE after each epoch
You need to fill in two parts:
4a. Forward Pass
Call forward() on the current data point to get each of the layer outputs and the model’s prediction for the current data point. Store the results in variables called:
fc1_output, relu_output, fc2_output, sigmoid_output, pred.
4b. Error computation
The error for one data point is the difference between the prediction and the true label:
\[\text{error} = \text{prediction} - y\]The prediction is pred (the output of the last FC layer). Store the result of this in a variable named error so it can be used in the backward pass. Add the square of this current error to the squared_error accumulator variable that is initialized to 0 outside of the indices loop. This variable will be used to compute RMSE at the end of each epoch.
(For one data point, the squared error is error ** 2.)
Later on in train, we use the value of squared error to help compute RMSE (root mean squared error, the square root of the average of the squared errors across all data points).
Part 5: Predict
NeuralNet.predict(X) is used to obtain the model’s prediction on the test dataset X. Call forward() and return just the predictions from that function.
The Dataset
You will use the same YearPredictionMSD dataset as in Lab 9. The training and testing data live in the data folder in the same directory as neural_net.py. The load_msd_data() function handles loading, normalizing, and shifting years by 1922 so the numbers are easier for the network to work with. Do not modify this function.
Running Your Code
Run neural_net.py directly. It will find the data folder automatically as long as data is in the same directory as neural_net.py. Make sure that YearPredictionMSD_train.txt and YearPredictionMSD_test.txt are in the data folder, and that the data folder is in the lab_10 directory along with neural_net.py.
Expected output:
Sample predictions with untrained network: # Actual year Predicted Error 1 2007 1922 -85 2 2003 1922 -81 3 2005 1922 -83 4 2003 1922 -81 5 2005 1922 -83 Starting 3-Layer Neural Network Training... Epoch 0: RMSE 29.66 Epoch 1: RMSE 9.84 Epoch 2: RMSE 9.37 Epoch 3: RMSE 8.88 Epoch 4: RMSE 8.54 Epoch 5: RMSE 8.37 Epoch 6: RMSE 8.25 Epoch 7: RMSE 8.17 Epoch 8: RMSE 8.10 Epoch 9: RMSE 8.03 Epoch 10: RMSE 7.96 Epoch 11: RMSE 7.92 Epoch 12: RMSE 7.85 Epoch 13: RMSE 7.77 Epoch 14: RMSE 7.74 Epoch 15: RMSE 7.67 Epoch 16: RMSE 7.65 Epoch 17: RMSE 7.63 Epoch 18: RMSE 7.56 Epoch 19: RMSE 7.51 Epoch 20: RMSE 7.48 Epoch 21: RMSE 7.43 Epoch 22: RMSE 7.42 Epoch 23: RMSE 7.40 Epoch 24: RMSE 7.33 Epoch 25: RMSE 7.29 Epoch 26: RMSE 7.29 Epoch 27: RMSE 7.23 Epoch 28: RMSE 7.23 Epoch 29: RMSE 7.19 Epoch 30: RMSE 7.15 Epoch 31: RMSE 7.14 Epoch 32: RMSE 7.12 Epoch 33: RMSE 7.08 Epoch 34: RMSE 7.04 Epoch 35: RMSE 7.06 Epoch 36: RMSE 7.04 Epoch 37: RMSE 6.99 Epoch 38: RMSE 6.94 Epoch 39: RMSE 6.94 Epoch 40: RMSE 6.89 Epoch 41: RMSE 6.86 Epoch 42: RMSE 6.85 Epoch 43: RMSE 6.83 Epoch 44: RMSE 6.80 Epoch 45: RMSE 6.77 Epoch 46: RMSE 6.74 Epoch 47: RMSE 6.71 Epoch 48: RMSE 6.69 Epoch 49: RMSE 6.66 Sample predictions with trained network: # Actual year Predicted Error 1 2007 1995 -12 2 2003 2003 0 3 2005 2003 -2 4 2003 2004 1 5 2005 2004 -1 ----------------------------------- Neural Network RMSE: 6.81 years Linear Regression RMSE: 7.30 years -----------------------------------
The first set of outputs demonstrates the untrained neural network’s predictions for a sample of 5 songs: that is, the predictions after we initialize all the \(W\)’s and \(b\)’s to small numbers. As you can see, we get the same prediction for all the data points, and that prediction is pretty far off the correct values. Once we train for 50 epochs and obtain the predictions for the same 5 songs, our neural network performs a lot better.
Notice that after 50 epochs, our neural net achieves a lower RMSE (meaning its predictions are off by less) than linear regression. With various adjustments, we could likely build a model that does even better, but we’ll leave that for another course.
How to Submit
- When ready to submit, visit the autograder.
- Submit only your
neural_net.pyfile.
IMPORTANT: For all labs in EECS 183, to receive a grade, every student must individually submit the Lab Submission. Late submissions for Labs will not be accepted for credit. For this lab, you will receive ten submissions per day with feedback.
- Once you receive full points from the autograder, you will have received full credit for this lab.
Copyright and Academic Integrity
© 2026 Steven Bogaerts.
Materials for this assignment were developed with assistance from course staff, including Krithika Venkatasubramanian.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

All materials provided for this course, including but not limited to labs, projects, notes, and starter code, are the copyrighted intellectual property of the author(s) listed in the copyright notice above. While these materials are licensed for public non-commercial use, this license does not grant you permission to post or republish your solutions to these assignments.
It is strictly prohibited to post, share, or otherwise distribute solution code (in part or in full) in any manner or on any platform, public or private, where it may be accessed by anyone other than the course staff. This includes, but is not limited to:
- Public-facing websites (like a personal blog or public GitHub repo).
- Solution-sharing websites (like Chegg or Course Hero).
- Private collections, archives, or repositories (such as student group “test banks,” club wikis, or shared Google Drives).
- Group messaging platforms (like Discord or Slack).
To do so is a violation of the university’s academic integrity policy and will be treated as such.
Asking questions by posting small code snippets to our private course discussion forum is not a violation of this policy.